mit6.5840 lab2D:Raft日志压缩
本文最后更新于:5 个月前
mit6.5840 lab2D:Raft日志压缩
写在前面
本篇先讲一下日志压缩相关内容,再对lab2做一个总览。
正文
1 为什么需要日志压缩?
Raft的日志在正常运行时会增长,以容纳更多的客户端请求,但在实际系统中,它不能无限制地增长。随着日志变长,它会占用更多空间并需要更多时间来重播。 如果没有某种机制来丢弃日志中积累的过时信息,这最终会导致可用性问题。也因此我们使用Snapshot(快照)来简单的实现日志压缩。
2 Snapshot机制
2.1 原理
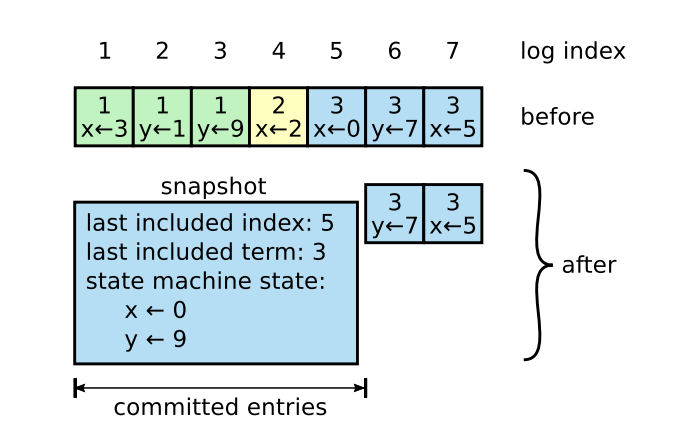
假设现在log中存储了x、y的更新信息。x的更新信息依次是3、2、0、5。y的更新信息依次是1、9、7。且日志下标1~5的日志被commit了,说明这段日志已经不再需要对当前节点来说已经不再需要。那么我们就存取这段日志的最后存储信息当做日志也就是x=0,y=9的时候并记录最后的快照存储的日志下标(last included index)以及其对应的任期。此时我们新的日志就只需要6、7未提交的部分,log的长度也从7变为了2。也因此可以看出快照存储是根据raft节点的个数决定。每个节点都会存取自身的快照,快照的信息就相当于commit过后的日志。
2.2 何时使用
回到raft的日志增量中,其实我们可以发现,commit更新的流程其实是,Leader发送给各个节点进行同步日志,然后返回给leader同步RPC的结果,更新matchIndex。如果超过半数节点已经同步成功后的日志,那么leader会把超过半数,且最新的matchIndex设为commitIndex,然后再由提交ticker进行提交。然后在下一次发送日志心跳时再更新followers的commitIndex下标。也因此就会可能有半数的节点,又或是网络分区,crash的节点没有更新到已提交的节点,而这段已提交的日志已经被leader提交而抛弃了。那么这个时候就需要leader发送自身的快照,安装给这些followers。
2.3 缺点
- 快照设置频繁下带来的浪费磁盘带宽和能源问题。当然快照设置不过与频繁也会导致存储问题。因此合理的安装快照才是正确的解决办法。 Paper中提到的策略就是对Log设置一个合理的大小,超过这个大小就进行日志快照的更新。
- 另外的就是在写入快照时进行的时间开销。因为可能在写入快照时会有竞争,并加锁。paper中提到的也是经典copy-on-write方法,在更新快照时,先临时储存一份log的备份。
3 实现函数
在单个节点中的Service层会对Raft节点调用Snapshot与CondInstallSnap两个函数,这也是lab中需要我们去编写的。对于自身的Raft节点来说需要对快照信息进行持久化的保存,也就是SaveStateAndSnapshot函数,这一部分的持久化信息会通过Service层用ReadSnapshot进行调用。这两个关于持久化的函数,lab已经为我们在persist.go中提供好了。而对于节点之间的快照联系的话则是通过InstallSnapshot进行节点之间的沟通。这就取决于谁是leader了。
3.1 Snapshot:更新自身快照
因为Snapshot其实就是service对raft调用的,使raft节点更新自身的快照信息。这样有的人可能会认为这样违反了Raft的强领导者原则。 因为跟随者可以在领导者不知情的情况下更新自己的快照。但是其实这种情况其实是合理的,更新快照只是为了更新数据,与达成共识并不冲突。数据仍然只是从领导者流向下层,followers只是通过快照去减轻它们的存储负担。
1 | |
3.2 CondInstallSnap:避免冲突
对于这个函数结合introduction中的解释其实也很好理解,其实就是你发送了快照,那么你发送的快照就要上传到applyCh,而同时你的appendEntries也需要进行上传日志,可能会导致冲突。可实际上,只要你在applied的时候做好同步,加上互斥锁。那么就可以避免这个问题,所以因此lab中也提到这个api已经是废弃的,不鼓励去实现,简单的返回一个true就行。
1 | |
3.3 InstallSnapShot:RPC
之前也提到了,发送快照的时机其实就是,就是leader发送给follower时的日志已经被抛弃了。那么此时需要发送快照。那么因此发送快照的调用入口应该在进行日志增量时的日志检查。而查询的条件就是rf.nextIndex[server]-1 < rf.lastIncludeIndex。
1 | |
写在后面
lab2大结局。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!