本文最后更新于:6 个月前
mit6.5840 lab2B:Raft日志同步
写在前面
这一节实现上一节中未实现的日志增量内容,去看2b的test可以发现其实是调用raft中的start函数,对leader节点写入log,然后检测log是否成功其实就是通过applyChan协程一直检测,可以自己多去看看test的源码。然后具体的代码编写、字段其实paper中也提到了,包括一些实现的细节也在figure中有提到。
为减少代码冗余,本文只描述新增加或修改的代码。
正文
1 Raft结构体新增applyChan
2 ticker:初始日志同步
对比2A增加了实现发送初始日志包。nextIndex代表的其实是代表下一次发送的日志的index代表哪里,paper中的表格也有体现。因此剪切发送的log也是根据这个来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
case Leader:
appendNums := 1
rf.timer.Reset(HeartBeatTimeout)
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
appendEntriesArgs := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: 0,
PrevLogTerm: 0,
Entries: nil,
LeaderCommit: rf.commitIndex,
}
appendEntriesReply := AppendEntriesReply{}
appendEntriesArgs.Entries = rf.logs[rf.nextIndex[i]-1:]
if rf.nextIndex[i] > 0 {
appendEntriesArgs.PrevLogIndex = rf.nextIndex[i] - 1
}
if appendEntriesArgs.PrevLogIndex > 0 {
appendEntriesArgs.PrevLogTerm = rf.logs[appendEntriesArgs.PrevLogIndex-1].Term
}
go rf.sendAppendEntries(i, &appendEntriesArgs, &appendEntriesReply, &appendNums)
}
}
|
3 日志增量 rpc构造
3.1 增加两种追加日志状态
1
2
3
4
5
6
7
| const (
AppNormal AppendEntriesState = iota
AppOutOfDate
AppKilled
AppCommitted
Mismatch
)
|
3.2 AppendEntriesReply新增UpNextIndex
1
2
3
4
5
6
| type AppendEntriesReply struct {
Term int
Success bool
AppState AppendEntriesState
UpNextIndex int
}
|
3.3 修改AppendEntries
有两个情况会导致conflict:
- 如果preLogIndex大于当前日志的最大的下标说明跟随者缺失日志,拒绝附加日志
- 如果preLog的任期和preLogIndex处的任期和preLogTerm不相等,那么说明日志存在conflict, 拒绝附加日志
追加到自身后,要记得进行将该log提交至chan中。也因此是应该追加的更新逻辑是,追加到自身rf.logs中后你需要先更新自身的commitIndex至追加后的长度,但是这时还没apply, lastApplied应该是真正提交到chan的下标,等commit更新后去提交到chan里再更新apply。这也是容易混乱的点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.killed() {
reply.AppState = AppKilled
reply.Term = -1
reply.Success = false
return
}
if args.Term < rf.currentTerm {
reply.AppState = AppOutOfDate
reply.Term = rf.currentTerm
reply.Success = false
return
}
if args.PrevLogIndex > 0 && (len(rf.logs) < args.PrevLogIndex || rf.logs[args.PrevLogIndex-1].Term != args.PrevLogTerm) {
reply.AppState = Mismatch
reply.Term = rf.currentTerm
reply.Success = false
reply.UpNextIndex = rf.lastApplied + 1
return
}
if args.PrevLogIndex != -1 && rf.lastApplied > args.PrevLogIndex {
reply.AppState = AppCommitted
reply.Term = rf.currentTerm
reply.Success = false
reply.UpNextIndex = rf.lastApplied + 1
return
}
rf.currentTerm = args.Term
rf.votedFor = args.LeaderId
rf.status = Follower
rf.timer.Reset(rf.overtime)
reply.AppState = AppNormal
reply.Term = rf.currentTerm
reply.Success = true
if args.Entries != nil {
rf.logs = rf.logs[:args.PrevLogIndex]
rf.logs = append(rf.logs, args.Entries...)
}
for rf.lastApplied < args.LeaderCommit {
rf.lastApplied++
applyMsg := ApplyMsg{
CommandValid: true,
CommandIndex: rf.lastApplied,
Command: rf.logs[rf.lastApplied-1].Command,
}
rf.applyChan <- applyMsg
rf.commitIndex = rf.lastApplied
}
return
}
|
3.4 sendAppendEntries新增三种状态处理
对于一轮发送的日志请求,与vote一致,超过半数节点就可以更新自身的commitIndex,并apply至客户端,对于一些返回的任期比自己大的reply那么说明肯定是经历了网络分区,需要进行投票重排。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
case AppNormal:
{
if reply.Success && reply.Term == rf.currentTerm && *appendNums <= len(rf.peers)/2 {
*appendNums++
}
if rf.nextIndex[server] > len(rf.logs)+1 {
return
}
rf.nextIndex[server] += len(args.Entries)
if *appendNums > len(rf.peers)/2 {
*appendNums = 0
if len(rf.logs) == 0 || rf.logs[len(rf.logs)-1].Term != rf.currentTerm {
return
}
for rf.lastApplied < len(rf.logs) {
rf.lastApplied++
applyMsg := ApplyMsg{
CommandValid: true,
Command: rf.logs[rf.lastApplied-1].Command,
CommandIndex: rf.lastApplied,
}
rf.applyChan <- applyMsg
rf.commitIndex = rf.lastApplied
}
}
return
}
case Mismatch:
if args.Term != rf.currentTerm {
return
}
rf.nextIndex[server] = reply.UpNextIndex
case AppCommitted:
if args.Term != rf.currentTerm {
return
}
rf.nextIndex[server] = reply.UpNextIndex
}
|
运行结果
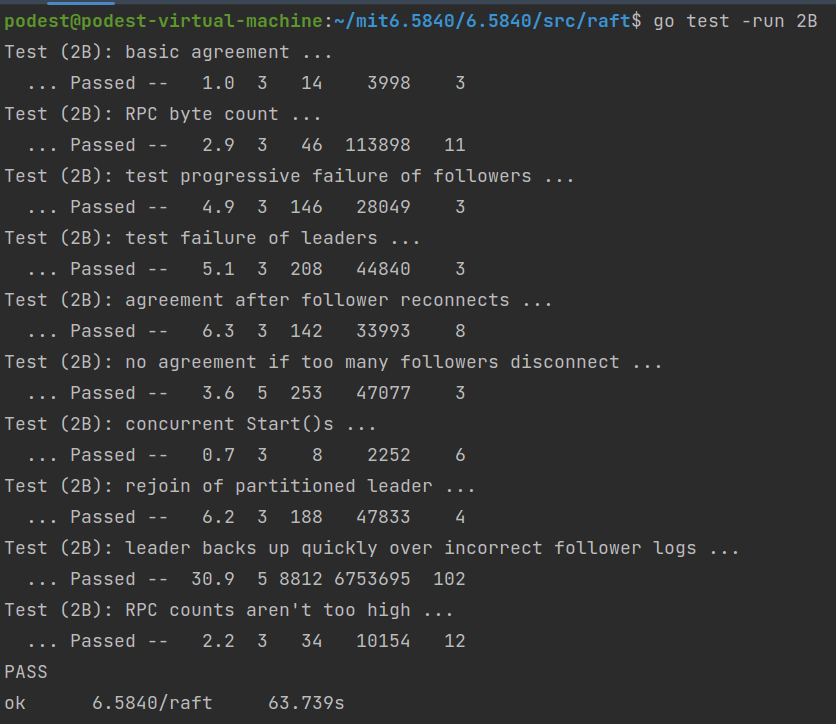
难度非常大的一节,代码量稍微上去了一些,主要难点在于排错…