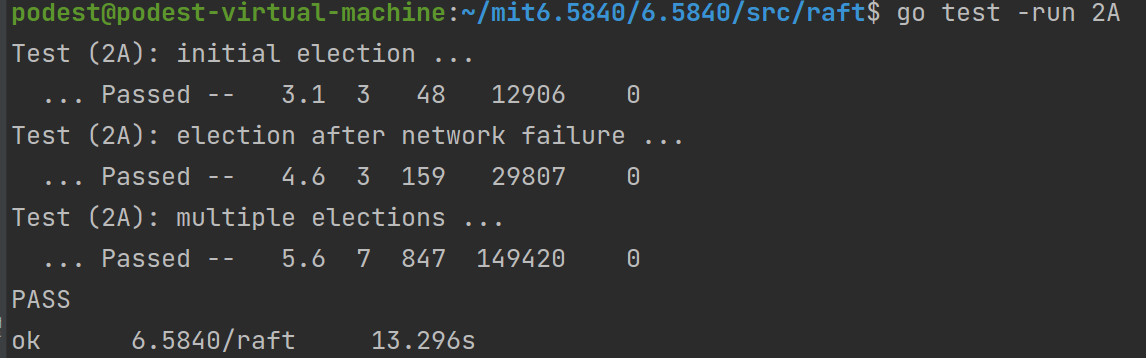
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| func (rf *Raft) ticker() {
for rf.killed() == false {
select {
case <-rf.timer.C:
if rf.killed() {
return
}
rf.mu.Lock()
switch rf.status {
case Follower:
rf.status = Candidate
fallthrough
case Candidate:
rf.currentTerm += 1
rf.votedFor = rf.me
votedNums := 1
rf.overtime = time.Duration(150+rand.Intn(150)) * time.Millisecond
rf.timer.Reset(rf.overtime)
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
voteArgs := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: len(rf.logs) - 1,
LastLogTerm: 0,
}
if len(rf.logs) > 0 {
voteArgs.LastLogTerm = rf.logs[len(rf.logs)-1].Term
}
voteReply := RequestVoteReply{}
go rf.sendRequestVote(i, &voteArgs, &voteReply, &votedNums)
}
case Leader:
appendNums := 1
rf.timer.Reset(HeartBeatTimeout)
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
appendEntriesArgs := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: 0,
PrevLogTerm: 0,
Entries: nil,
LeaderCommit: rf.commitIndex,
}
appendEntriesReply := AppendEntriesReply{}
go rf.sendAppendEntries(i, &appendEntriesArgs, &appendEntriesReply, &appendNums)
}
}
rf.mu.Unlock()
}
}
}
|